Andrew Ng 교수님의 Machine Learning Specialization 강의를 정리한 내용입니다.
Coursera가 아닌 네이버 부스트코스에서 제공하는 버전을 수강하고 있습니다.
강좌 소개
Deep Learning은 전기가 세상에 등장했던 것처럼 많은 산업을 변화시키고 있습니다. 이미 헬스케어, 자율주행 등 일상에도 많이 사용되고 있습니다.
Neural Network와 Deep Learning을 배우는 이 강좌의 최종 목표는 전통적으로 고양이를 인식하는 모델을 만드는 것입니다. 목차는 다음과 같습니다.
- Neural Network, Deep Learning 기초
- 하이퍼파라미터를 통해 Deep Neural Network 향상하기
- Machine Learning 프로젝트 구성하기
- Convolutional Neural Networks
- 시퀀스 모델 만들기로 Natural Language 프로세스 알아보기
신경망은 무엇인가?
Course 1 에서 사용했던 집값 예측 예시는 계속 사용될 예정입니다. 가장 간단한 Neural Network는 집의 크기값이 들어오고, 단일 neuron을 통과하면서 예상한 집값 price가 결과로 나오는 것으로 예시를 들 수 있습니다.

하나의 neuron이 의미하는 것은 ReLU(Rectified Linear Unit) 함수일 수도 있습니다. 집 크기와 집값의 상관관계를 나타내는 데이터가 선형성을 띄고 있지만, 음수값은 없으니까 아래 그림의 파란선과 같이 ReLU 함수 모양을 가질 수 있습니다.

더 큰 Neural Network는 여기에서 더 많은 neuron이 블럭처럼 쌓여서 연결되어 있다고 생각하면 됩니다.

집값 예측 모델로 Neural Network를 그림으로 표현하자면 위 그림과 같습니다. 우리는 input x와 output y만 넣어줍니다. 그 안에 family size, walkability, school quality 등은 모델이 알아내게 하며, hidden layer라고 불립니다. 충분한 x와 y로 이뤄진 훈련데이터를 입력한다면, 예측을 정확하게 하는 hidden unit에 들어가는 함수를 알 수 있습니다. Hidden unit에 들어가는 함수는 앞에서 본 ReLU 함수가 될 수도 있고 다른 비선형 함수가 될 수도 있습니다. 입력값 x 4개를 예시로 들었는데, hidden unit에 도움이 안되는 input이어도 모두 함수에 들어가게 할 것이며, 함수가 알아서 값을 조절해 출력값 y를 예측할 것입니다.
신경망을 이용한 지도학습
| Input(x) | output(y) | 응용 |
| 집 정보 | 가격 | 부동산 |
| 광고, 고객정보 | 광고를 클릭했느냐? (0/1) | 온라인 광고 |
| 이미지 | 객체 (1,…,1000) | 사진 태그 |
| 오디오 | 텍스트 번역본 | 음성인식 |
| 영어 | 중국어 | 기계번역 |
| 이미지, 라이다 정보 | 다른차 위치 | 자율주행 |
지도학습(supervised learning)은 많은 경제적 가치를 창출해왔습니다. 표에 나온 예시는 지도학습의 예시인데, 부동산 가격 예측, 온라인 광고가 일반적인 neural network를 이용한 지도학습입니다. 이미지를 입력값으로 받는 Image classification은 CNN을 활용하며, 음성인식이나 번역에 사용되는 RNN이 있습니다. 오디오와 같은 시퀀스 데이터는 1차원의 시계열로 표현할 수 있는 데이터로 이후에 배울 예정입니다.
Structured vs. Unstructured Data
지도학습에서 데이터 종류에 따라 structured, unstructured로 나뉩니다. structured data는 database에 저장되는 tabular 데이터를 생각해볼 수 있겠고, unstructured data는 음성파일, 이미지, 텍스트 등이 있겠습니다. 학습에 쓰이는 input feature로는 이미지는 개별 픽셀값, 텍스트는 각 단어가 됩니다. 사람에게는 쉽지만 기계에게는 학습하기 어려운 것들이 주로 unstructured data입니다. 신경망은 컴퓨터가 더 어려워하는 unstructured data를 이해하는 데에 도움을 많이 주었습니다. 그렇지만 이제까지 structured 데이터 기반의 정확한 알고리즘들이 돈을 더 많이 벌어왔습니다. Unstructured data를 활용하는 알고리즘은 사람들이 더 신기해하고, 직관적으로 어떤 의미인지 알게 되는, 왜 해야하는지 아는 그런 알고리즘입니다.
Why is deep learning taking off?
Deep learning neural network의 개념은 오랫동안 존재해왔지만 최근에 더 뜨게 된 분야입니다. 이전에는 적은 training만 가능했으나 세상의 디지털 환경이 더 갖춰지면서 data 양은 증가하였고 알고리즘 성능은 올라가게 되었습니다.
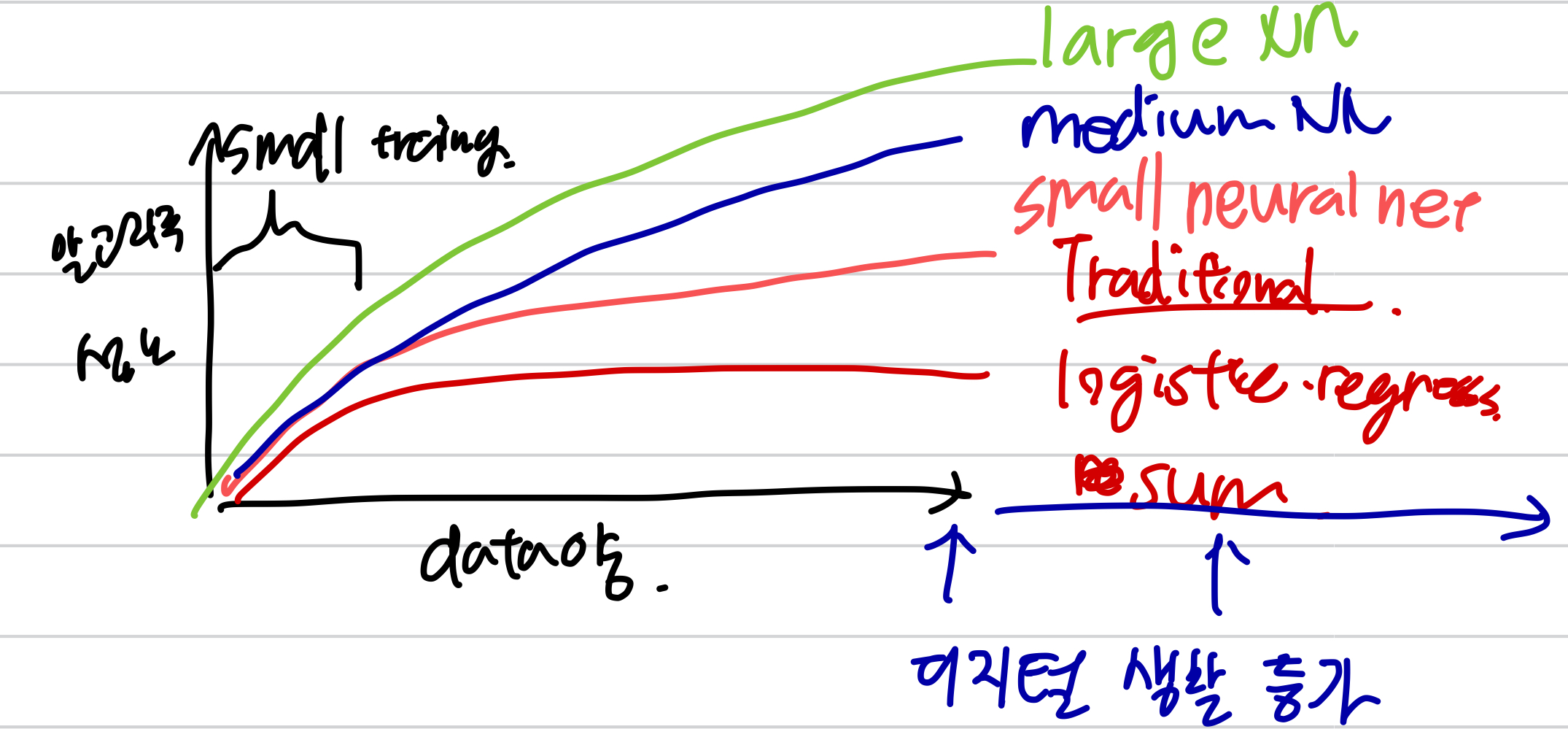
위 그래프로 파악할 수 있는 두 가지는 1. 좋은 성능은 더 큰 neural network에서 보였고, 2. 많은 데이터가 더 좋은 성능을 보였다는 것입니다. Scale이 커지는 것이 딥러닝의 발전을 주도 했는데, scale이 커진다는 것은 neural network의 connection, parameter의 증가를 의미합니다. 데이터가 적다면 오히려 SVM과 같은 간단한 모델이 더 좋은 성능을 보일 수도 있습니다.
초창기 deep learning은 data, computation, algorithm 측면의 한계가 모두 있었고, 세 가지 모두 혁신이 있었지만, 특히 algorithms 혁신으로 신경망이 빠르게 실행됨으로써 발전을 많이 했습니다. 한가지 예를 들면, sigmoid 함수를 기계학습에 사용했을 때, 양수 음수 둘 다 값이 커지면 미분값은 0에 가까워지고 경사하강법에서 파라미터값이 적게 업데이트 됨으로써 기계학습의 학습(train)이 매우 느려진다는 단점을 가지고 있었습니다. 그러나 activation function으로 ReLU 함수를 사용하면서 미분한 기울기 값이 0에 수렴할 확률이 낮아 졌습니다. 이를 통해 알고리즘의 학습 속도가 올라갔습니다. Neural Network는 연역적 판단보다는 귀납적 판단을 하는 모델이기 때문에 빠르게 계산이 가능하면서 더 많은 실험을 할 수 있고 궁극적으로 모델 발전에 좋은 선순환 구조를 만들었습니다. 즉, 선순환 구조로 더 많은 아이디어를 code로 작성하고 더 많은 experiment를 도출하는 구조를 만들어서 deep learning 을 최적화 하였고, 좋은 결과물을 내놓을 수 있었습니다.

[기술 용어 정리]
SVM: Support Vector Machine, 주어진 데이터가 어느 카테고리에 속할까 판단하는 이진 선형 분류 모델입니다.
[영어 단어 정리]
- rectify: 조정하다
- hype: 과장 광고
- recursive: 재귀적, 순환적
- take off: 인기를 얻다, 유행하다
[출처]
- 강의: https://youtu.be/CS4cs9xVecg



